La creación de imágenes realistas a partir de descripciones de texto ha sido un desafío en el campo de la inteligencia artificial durante mucho tiempo. Ahora, un equipo de investigadores chi nos ha desarrollado una red neuronal generativa adversarial llamada CD-GAN que utiliza el conocimiento común para generar imágenes de alta calidad a partir de descripciones de texto.
El reto de la síntesis de imágenes a partir de texto
La creación de imágenes a partir de texto es un reto en el campo de la inteligencia artificial debido a la complejidad de la tarea. Por ejemplo, si se describe un pájaro, se deben tomar decisiones sobre su tamaño, color y forma, así como sobre detalles más específicos, como la posición de las piernas o el ángulo de la cabeza. Esto requiere un conocimiento profundo de la estructura y apariencia de los objetos en cuestión.
La solución: CD-GAN
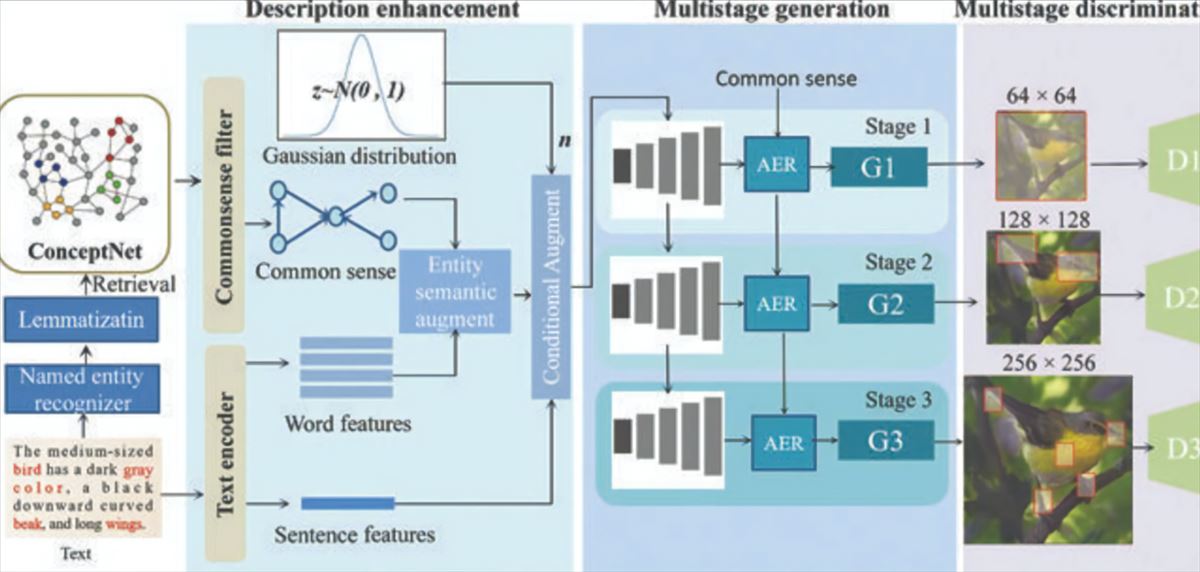
Para abordar este desafío, el equipo de investigación chino desarrolló CD-GAN, una red neuronal generativa adversarial que utiliza el conocimiento común para mejorar la síntesis de imágenes a partir de texto. CD-GAN consta de tres módulos principales: descripción mejorada, generación multietapa y discriminación multietapa.
Descripción mejorada
El primer módulo, la descripción mejorada, utiliza la base de datos ConceptNet para agregar conocimiento común relevante a la descripción de texto original. ConceptNet es una fuente de conocimiento general que se utiliza en el procesamiento del lenguaje natural para crear gráficos de nodos relacionados. Una vez que se agregó la información relevante de ConceptNet a la descripción original, se añadió ruido estadístico para introducir aleatoriedad en las imágenes generadas.
Generación multietapa
El segundo módulo de CD-GAN es la generación multietapa. Este módulo utiliza un enfoque de «refinamiento de entidad adaptativa» para generar imágenes de alta calidad en varias etapas. Cada etapa corresponde a un tamaño de imagen diferente, comenzando con una imagen pequeña de 64 x 64 píxeles y aumentando a 128 x 128 y luego a 256 x 256 píxeles. La red utiliza el conocimiento común para determinar los detalles necesarios en cada etapa.
Discriminación multietapa
El tercer módulo, la discriminación multietapa, verifica que las imágenes generadas coincidan con la descripción de texto original. Este proceso es importante porque garantiza que las imágenes generadas sean fieles a la descripción original. La verificación de la descripción original también mejora la calidad de la imagen generada, ya que ayuda a la red a enfocarse en los detalles importantes.
Resultados y aplicaciones futuras
La red neuronal CD-GAN fue entrenada utilizando el conjunto de datos Caltech-UCSD Birds-200-2011, que contiene más de 11,000 imágenes de aves. Los resultados de la red fueron muy prometedores, con imágenes generadas que eran naturalistas, nítidas y coherentes con la descripción original. Los puntajes cuantitativos también demostraron que la CD-GAN superó a los métodos de redes neuronales generativas anteriores en términos de fidelidad y distancia de las imágenes reales.
La aplicación más prometedora de CD-GAN es en la industria del entretenimiento y los videojuegos. La capacidad de generar imágenes realistas a partir de descripciones de texto podría ayudar a los desarrolladores de juegos a crear entornos virtuales más detallados y realistas. Además, la tecnología también podría tener aplicaciones en campos como el diseño de interiores, la moda y la publicidad.
Aunque la CD-GAN es una gran avance en la síntesis de imágenes a partir de texto, todavía hay mucho trabajo por hacer en este campo. Uno de los mayores desafíos es mejorar la comprensión de la red de la semántica y la estructura del lenguaje natural. La incorporación de más conocimiento común y la mejora de la capacidad de la red para reconocer objetos complejos podrían mejorar aún más la calidad de las imágenes generadas.
En resumen, la CD-GAN es un gran paso adelante en la síntesis de imágenes a partir de texto. Al incorporar conocimiento común en la generación de imágenes, la red es capaz de crear imágenes realistas y detalladas que se ajustan a la descripción original. A medida que la tecnología continúa evolucionando, es emocionante pensar en las muchas aplicaciones que tendrá esta tecnología en el futuro.
☞ El artículo completo original de Juan Diego Polo lo puedes ver aquí
No hay comentarios.:
Publicar un comentario